class: center, middle, inverse, title-slide # MLCA Week 11: ## Support Vector Machines ### Mike Mahoney ### 2021-11-10 --- Before we get started, I've got a little bit of housekeeping to go over. This is our last week of regular class. The next two classes (weeks 12 and 13) are dedicated time to work on your course project. I'll still be in Bray 300 during class time if you have questions or want help with your project, and I'll still be holding my regular office hours. That said, if you don't think coming to class will be a productive way for you to spend your time, that's totally fine. Four weeks from now (week 14, 2021-12-08, our last day of class) everyone will share their final presentation on the project. You should hand in all your files (report, data, and code) by the start of that class. --- Your final presentation should be about five minutes (or less). Ideally you'll talk about the problem you wanted to solve, the methods you used, and how well it went. You can use slides if you want, or you can feel free to just talk about your project for five minutes. The presentations are meant as an opportunity for us to find out what everyone else has been working on; they should not feel like a high-stakes event. Your code should run immediately when I load it on my computer and return the same results as you report; this means no hard-coded file paths or `setwd` calls (use the "here" package instead) and `set.seed` used before randomization. As usual, feel free to reach out with any questions or concerns. --- class: center middle # Support Vector Machines --- .bg-washed-green.b--dark-green.ba.bw2.br3.shadow-5.ph4.mt5[ Rule 1. New methods always look better than old ones. Neural nets are better than logistic regression, support vector machines are better than neural nets, etc. In fact it is very difficult to run an honest simulation comparison, and easy to inadvertently cheat by choosing favorable examples, or by not putting as much effort into optimizing the dull old standard as the exciting new challenger. Rule 2. Complicated methods are harder to criticize than simple ones. By now it is easy to check the efficiency of a logistic regression, but it is no small matter to analyze the limitations of a support vector machine. .tr[ — [Brad Efron: Comment on Statistical Modeling: The Two Cultures](https://projecteuclid.org/journals/statistical-science/volume-16/issue-3/Statistical-Modeling--The-Two-Cultures-with-comments-and-a/10.1214/ss/1009213726.full) ] ] --- class: middle We're wrapping up this course with one final type of model, the **support vector machine** (or SVM). SVMs are our second kernel-based method, and the most common kernel-based method in use today. SVMs are highly flexible, robust to outliers, and are resilent to overfitting. However, they can also be slow to train, particularly on data sets with many observations. As a result, SVMs are often viewed as more specialized models than random forests and GBMs. If nothing else is working right, it might be time to try an SVM. --- But before we get into all that, let's go back to our fake data from last week: <br /> <!-- --> --- Last week, we focused on classifying our mystery points (the purple triangle) based on its nearest neighbors -- if the majority of neighbors nearby were edge plants, we'd predict an edge plant. But there might be an easier way to classify things. There's a big gap between our two classes -- what if we drew a line across it? <!-- --> --- Now instead of having to find the neighbors for each point we want to predict, we can just look at where the point falls compared to the line. If the point is above the line, it's an edge plant; if it's below, it's an interior plant. When our data can be separated into two classes by a straight line, we call it **linearly separable**. We can think of the line as a **decision boundary**, because our predictions depend entirely on what side of the boundary a point falls. For instance, our mystery point here falls on the "Edge" side of the boundary, so we'd classify this point as an edge plant. <!-- --> --- Another name for this line is a **separating hyperplane**. Remember from way back in week 2 that we can call model surfaces in any dimension a hyperplane; rather than directly modeling an outcome or probability, however, these hyperplanes are trying to split our data into two classes. <!-- --> --- But how do we choose where to draw the decision boundary? There are many possible different separating hyperplanes that perfectly classify our data: <!-- --> Which one would we want to use as a decision boundary? --- Just by looking at the graph, we can tell that some of these hyperplanes seem "better" than others. How can we choose the "best"? One approach is to choose the hyperplane that is the _furthest_ from both classes. That _should_ maximize how generalizable the decision boundary is, so that a point with X and Y values a bit further out from the class mean will still be correctly classified. In order to find that furthest line, we need to first find the points from each class which are closest to the _other_ class: <!-- --> --- Then we draw the line that maximizes the distance of _both_ of those points from the line. We call this decision boundary the **optimal separating hyperplane**, and the points we use to draw it **support vectors**. <!-- --> --- This method maximizes the distance between the two classes (the area between the dotted lines, also known as a **margin**). Because we're drawing our decision boundary so that no points are inside the margin and no points are misclassified, we call this a **hard margin classifier**. This is the simplest version of a **support vector machine**. <!-- --> --- This simple hard-margin SVM has some weaknesses. For instance, let's look at a different data set, showing how income and lot size are associated with riding lawnmower ownership: <!-- --> (This graph adapted from [Hands-on Machine Learning with R](https://bradleyboehmke.github.io/HOML/svm.html#the-soft-margin-classifier).) --- This data is still linearly separable -- we could draw a straight line that would perfectly split our data set into two classes. However, this data set has a potential outlier here which will seriously impact how we split our data into classes: <!-- --> --- If we go through the same process as earlier to find our optimal separating hyperplane, we'll find that this decision boundary is much closer to the "Yes" point cloud than we'd expect. This probably won't generalize well -- as we test our model on new data, we're very likely to mischaracterize "Yes" points as "No"s! <!-- --> --- What if, rather than drawing our hyperplane so that there are no points inside the margin (like we do with the hard margin classifier), we allowed a few points to fall inside that space? That way, we could use other points as support vectors, making our SVM more resilient to outliers. This is known as the **soft-margin classifier** (because we've _softened_ the requirement that no points fall inside the margin). How many points we let inside the margin is an important hyperparameter of SVMs, usually referred to as `\(C\)`. --- If `\(C\)` is 0, you let 0 points inside the margin -- you use the points which are closest to each other as support vectors to produce the hard margin classifier. If `\(C\)` is infinite, you use the furthest removed points as support vectors and let all of your data into the margin. 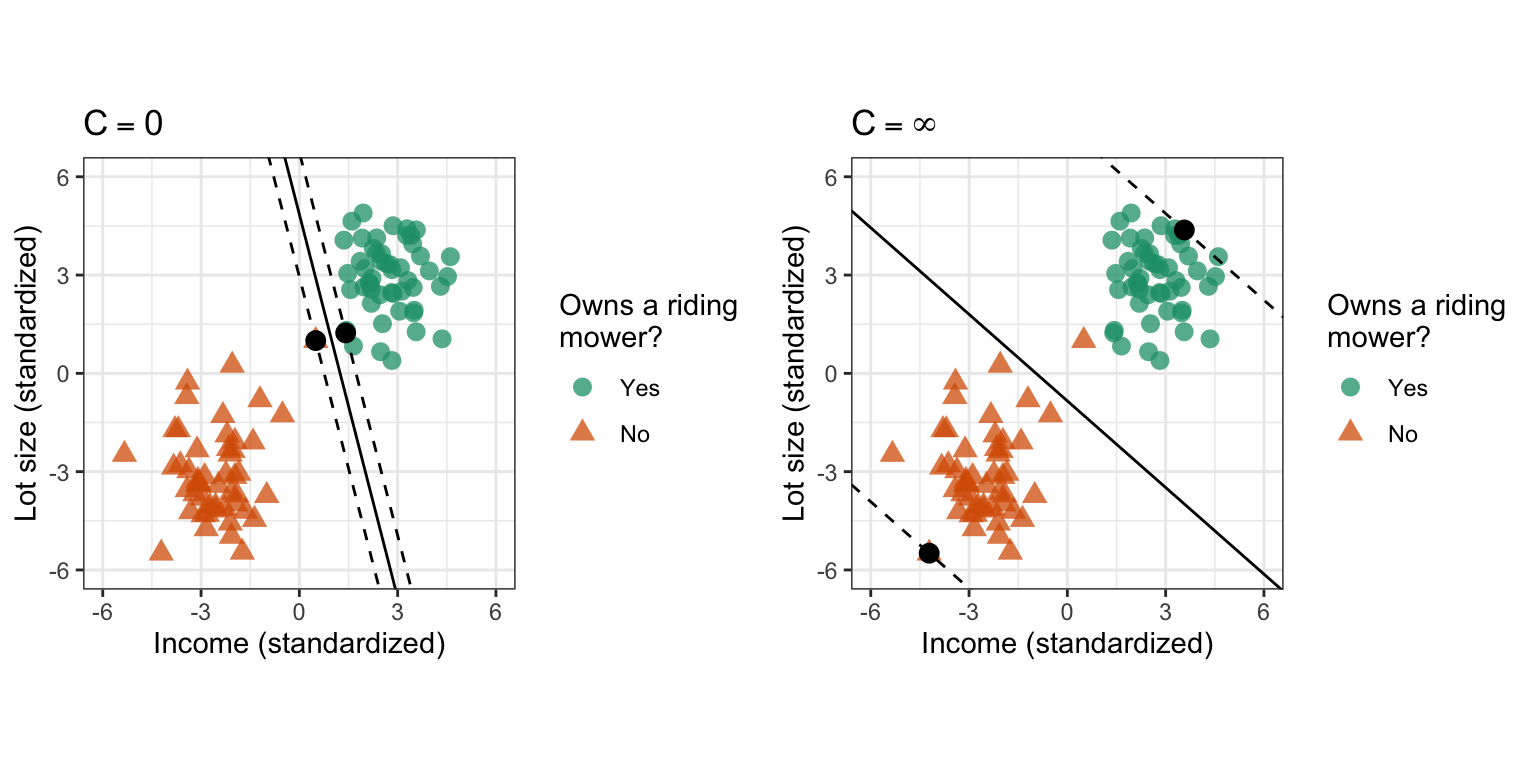 --- In practice, we almost always use soft margin classifiers when fitting SVMs. By deciding how many points are allowed inside the margin, we're able to find the linear decision boundary that best classifies training data while still generalizing well to the test set. But what if our data isn't linearly separable? This is pretty common in the real world -- if there was an obvious linear boundary between our two classes, we wouldn't need machine learning to tell them apart. Imagine a data set that looked like this, where our classes were mixed together: <!-- --> --- What if we could create a new variable so that our data was linearly separable in higher dimensions? For instance, imagine we created a new variable `\(Z\)` such that `\(Z = X^2 + Y^2\)`. If we use that variable to plot our data in 3D, it seems like we might be able to draw a linear decision boundary for our data: <!-- --> --- We can use that new Z variable to draw a linear decision boundary in higher-dimensional space than our original 2D X/Y graph. But when we come back to 2D (so plotting the hyperplane using only X and Y values), it's entirely nonlinear. By combining variables to cast your data into a higher-dimensional space to find linear decision boundaries, SVMs are able to approximate any non-linear relationships your predictors have with your outcome. <!-- --> --- In order to cast your data into higher dimensions, SVMs make use of what are known as _kernel functions_. Kernel functions are effectively a guess about how your variables are related to your outcome; they specify some transformation to your variables that will _hopefully_ make your data linearly separable. There are a number of different kernel functions available to choose from, each a different transformation which might work well for your data. In practice, we generally start with something called the "**radial basis function**" kernel (or RBF) and try out other kernels only if that one doesn't work. I'm intentionally avoiding getting too deep into the math of how kernel transformations work here; conceptually understanding that each kernel is a different equation to create new features from your existing variables should be enough. For details on the mathematical expression of each kernel, check out `?kernlab::dots`. --- One last thing before we move on to implementing SVMs in R. Just like KNNs, SVM are trying to calculate the distance between your points in order to find separating hyperplanes. This means that, just like with KNNs, you need to scale and center your data in order to make sure all your variables "count" for distance equally, regardless of units. This also means that, to an SVM, categorical variables (which are encoded to be either 0 or 1) have lower variance than continuous variables, and so tend to contribute less to the final prediction. If your data contains many categorical variables, SVM may make worse predictions than other methods. --- Alright, that's enough hyperdimensional thinking for today. Let's get down to brass tacks. We'll be using the `kernlab` package to fit SVMs today -- go ahead and install and load it now: ```r install.packages("kernlab") ``` ```r library(kernlab) ``` We'll also go ahead and set our attrition data set up for one last time: ```r library(modeldata) data(attrition) set.seed(123) row_idx <- sample(seq_len(nrow(attrition)), nrow(attrition)) training <- attrition[row_idx < nrow(attrition) * 0.8, ] testing <- attrition[row_idx >= nrow(attrition) * 0.8, ] ``` --- We're going to start off predicting attrition by fitting an SVM using an RBF kernel, which is the default method in the `ksvm` function we use to fit SVMs. That means that we can use `ksvm` to create our SVM using the exact same syntax as `lm`: ```r first_svm <- ksvm(Attrition ~ ., training) first_svm ``` ``` ## Support Vector Machine object of class "ksvm" ## ## SV type: C-svc (classification) ## parameter : cost C = 1 ## ## Gaussian Radial Basis kernel function. ## Hyperparameter : sigma = 0.0247042045168008 ## ## Number of Support Vectors : 520 ## ## Objective Function Value : -341.4969 ## Training error : 0.120851 ``` --- There's a few useful pieces of information in the output from `ksvm`: + We're told we're using a `Gaussian Radial Basis kernel function`, which is the formal name for the RBF kernel. + We can see the value of our `\(C\)` hyperparameter (which controls how "hard" the margin is), which by default is 1. + We're told that there's another hyperparameter `sigma` set to some extremely small value, which we haven't talked about at all. ```r first_svm ``` ``` ## Support Vector Machine object of class "ksvm" ## ## SV type: C-svc (classification) ## parameter : cost C = 1 ## ## Gaussian Radial Basis kernel function. ## Hyperparameter : sigma = 0.0247042045168008 ## ## Number of Support Vectors : 520 ## ## Objective Function Value : -341.4969 ## Training error : 0.120851 ``` --- Sigma (usually written `\(\sigma\)`) is what we call a **kernel hyperparameter**. While we'll have to tune our `\(C\)` hyperparameter no matter what kernel we use, if we chose to use a different kernel, we might have entirely different kernel hyperparameters. If you're using any non-RBF kernel, you can think of kernel hyperparameters just like any other hyperparameter -- a value you need to find through model tuning. However, when we're using RBF kernels, we're actually able to find `\(\sigma\)` without fitting a model at all. This lets us cut down the number of models we need to test when tuning hyperparameters -- when using RBF kernels, we only need to tune C! You can see a full list of the kernels available in `kernlab`, and their hyperparameters, via `?kernlab::dots`. --- `\(C\)` can be any positive number, which means there are a lot of potential values to check. A common recommendation is to start off by testing powers of 2 -- we'll try from 2^-8 to 2^8: ```r tuning_grid <- data.frame( C = 2^(-8:8), loss = NA ) tuning_grid ``` ``` ## C loss ## 1 0.00390625 NA ## 2 0.00781250 NA ## 3 0.01562500 NA ## 4 0.03125000 NA ## 5 0.06250000 NA ## 6 0.12500000 NA ## 7 0.25000000 NA ## 8 0.50000000 NA ## 9 1.00000000 NA ## 10 2.00000000 NA ## 11 4.00000000 NA ## 12 8.00000000 NA ## 13 16.00000000 NA ## 14 32.00000000 NA ## 15 64.00000000 NA ## 16 128.00000000 NA ## 17 256.00000000 NA ``` --- The next thing we need to do to tune our parameters is to write our loss function. But there's a hitch here: what loss can we use? SVMs classify points based entirely on what side of the decision boundary they fall on. By default, this doesn't generate probabilities for our points -- a point is either one side or the other. While there _are_ ways to get SVMs to generate probabilities (such as the `prob.model` argument to `ksvm`), they aren't very commonly used, which means using cross-entropy or AUC loss like we've done in the past is rare. --- Instead, we tend to use overall model accuracy as a loss function for SVMs. Of course, we've already seen how that can be a problem when we have imbalanced classes. For that reason, we're going to go ahead and resample our training set so that our classes are balanced before we tune our SVMs: ```r positive_training <- training[training$Attrition == "Yes", ] negative_training <- training[training$Attrition == "No", ] n_pos <- nrow(positive_training) resampled_positives <- sample(1:n_pos, size = 5 * n_pos, replace = TRUE) resampled_positives <- positive_training[resampled_positives, ] resampled_training <- rbind( negative_training, resampled_positives ) ``` --- And now we can go ahead and write a function to calculate overall model accuracy. When we predict with our SVM, we'll get a set of class predictions -- so for our attrition data, we'll get either Yes or No predictions. We can use those in a function to calculate overall accuracy like this: ```r calc_accuracy <- function(model, data) { matching <- predict(model, data) == data$Attrition sum(matching) / length(matching) } ``` --- We can plug `calc_accuracy` right into our same old `k_fold_cv` function: ```r k_fold_cv <- function(data, k, ...) { per_fold <- floor(nrow(data) / k) fold_order <- sample(seq_len(nrow(data)), size = per_fold * k) fold_rows <- split( fold_order, rep(1:k, each = per_fold) ) vapply( fold_rows, \(fold_idx) { fold_test <- data[fold_idx, ] fold_train <- data[-fold_idx, ] fold_svm <- ksvm(Attrition ~ ., fold_train, ...) calc_accuracy(fold_svm, fold_test) }, numeric(1) ) |> mean() } ``` --- The code to loop through our tuning grid is then pretty simple: ```r for (i in seq_len(nrow(tuning_grid))) { tuning_grid$loss[i] <- k_fold_cv( resampled_training, 5, C = tuning_grid$C[i] ) } ``` We can look at how accuracy changes as we try different values of C: ```r library(ggplot2) ggplot(tuning_grid, aes(C, loss)) + geom_point() + geom_line() ``` <!-- --> --- It looks like higher C values are more effective here! We'll run with C = 64 for now - that's where we got the little bump in the top of our curve. As usual, we can then go on and fit our final model on the entire training set: ```r final_svm <- ksvm( Attrition ~ ., resampled_training, C = 64 ) ``` We could go ahead and use our `calc_accuracy` function to find the overall accuracy for this model: ```r calc_accuracy(final_svm, testing) ``` ``` ## [1] 0.8440678 ``` But as usual, looking at the overall accuracy obscures how well our model does at predicting each class. Instead, we'll look at the full confusion matrix on the next slide. This model has higher sensitivity but lower specificity than our random forest from back in week 7, and lower sensitivity and higher specificity than our logistic models from way week 4. Which of these models is "best" for your data is, as usual, a question of what you're looking for. --- ```r caret::confusionMatrix( predict(final_svm, testing), testing$Attrition, positive = "Yes" ) ``` ``` ## Confusion Matrix and Statistics ## ## Reference ## Prediction No Yes ## No 237 21 ## Yes 25 12 ## ## Accuracy : 0.8441 ## 95% CI : (0.7975, 0.8835) ## No Information Rate : 0.8881 ## P-Value [Acc > NIR] : 0.9916 ## ## Kappa : 0.2547 ## ## Mcnemar's Test P-Value : 0.6583 ## ## Sensitivity : 0.36364 ## Specificity : 0.90458 ## Pos Pred Value : 0.32432 ## Neg Pred Value : 0.91860 ## Prevalence : 0.11186 ## Detection Rate : 0.04068 ## Detection Prevalence : 0.12542 ## Balanced Accuracy : 0.63411 ## ## 'Positive' Class : Yes ## ``` --- So far, we've focused entirely on SVM as a classification model. However, SVMs can be used for regression as well! Sometimes referred to as **support vector regression** (or SVR), SVM-based regression models are excellent at modeling non-linear relationships between your predictors and outcome. Rather than casting your data into higher dimensions in an attempt to find an optimal separating hyperplane, SVR attempts to find a dimension where as many points lie along the hyperplane as possible -- that is, a dimension where your data can be captured perfectly by simple linear regression. When using SVMs for regression, we're no longer trying to keep as many points outside of our margin as possible. Instead, we want all of our points to fall on the hyperplane, or at the very least within a certain range of it. To avoid overfitting, we can control how wide that range is via a new hyperparameter, `\(\epsilon\)` (or "epsilon"). --- In practice, using SVMs for regression is pretty similar to when we used it for classification. We'll need to first re-create our Ames housing data: ```r ames <- AmesHousing::make_ames() row_idx <- sample(seq_len(nrow(ames)), nrow(ames)) training <- ames[row_idx < nrow(ames) * 0.8, ] testing <- ames[row_idx >= nrow(ames) * 0.8, ] ``` As well as our usual RMSE loss function: ```r calc_rmse <- function(model, data) { predictions <- predict(model, data) sqrt(mean((predictions - data$Sale_Price)^2)) } ``` --- We'll repurpose our `k_fold_cv` function as well, so that it's modeling `Sale_Price` as an outcome and using `calc_rmse` for loss: ```r k_fold_cv <- function(data, k, ...) { per_fold <- floor(nrow(data) / k) fold_order <- sample(seq_len(nrow(data)), size = per_fold * k) fold_rows <- split( fold_order, rep(1:k, each = per_fold) ) vapply( fold_rows, \(fold_idx) { fold_test <- data[fold_idx, ] fold_train <- data[-fold_idx, ] fold_svm <- ksvm(Sale_Price ~ ., fold_train, ...) calc_rmse(fold_svm, fold_test) }, numeric(1) ) |> mean() } ``` --- And now we'll set up our tuning grid! We're going to test similar values for C as we did with classification. `\(\epsilon\)`, meanwhile, tends to be a very small positive number, so we'll focus on testing possible values under 1: ```r tuning_grid <- expand.grid( C = 2^(-5:5), epsilon = 2^(-8:0), rmse = NA ) ``` With that work out of the way, we can use an almost identical loop to run each stage of our grid search: ```r for (i in seq_len(nrow(tuning_grid))) { tuning_grid$rmse[i] <- k_fold_cv( training, 5, C = tuning_grid$C[i], epsilon = tuning_grid$epsilon[i] ) } head(arrange(tuning_grid, rmse), 2) ``` ``` ## C epsilon rmse ## 1 2 0.0625 25239.68 ## 2 32 0.0625 25415.68 ``` --- And then, as usual, we can use the optimal values of our hyperparameters to evaluate how an SVM fit on the full training data performs against the test set: ```r final_svr <- ksvm( Sale_Price ~ ., training, C = 2, epsilon = 2^-4 ) calc_rmse(final_svr, testing) ``` ``` ## [1] 28110.08 ``` The answer is "not great" -- our random forest and GBMs have both posted better accuracy numbers. In this situation, we might start exploring other kernels, try a larger grid to find hyperparameters, or perhaps just accept that GBM is a better model for this data. --- And that's SVM: create new variables to find a linear surface that perfectly separates your classes or perfectly predicts your outcome, with the definition of "perfectly" controlled by `\(C\)` and `\(\epsilon\)`. SVM are not the best model for all situations. Like traditional regressions, SVM uses all predictors equally, and therefore perform worse with noisy data. SVM can also be slow to fit, and they don't always produce as accurate models as GBMs. So why do we talk about SVM at all? --- Well, on the one hand, sometimes SVM are actually the best model for your data. They can approximate smooth nonlinear relationships better than tree-based methods, whose hard binary thresholds create a lot of right-angles in the prediction surface. Additionally, the ability to change between different kernels makes SVM incredibly flexible for many tasks in machine learning. They might not be the first model you try for a given problem, but if nothing else is working then you may as well give SVM a go. --- But also, I think it's worth stepping through the timeline of the models we've gone over in this course. Linear regression, where we started, traces all the way back to 1805. Logistic regression first appears around 1838. Our next stop on the timeline was then KNN, first introduced in 1951, followed by decision trees in 1960. SVMs would then appear in 1992, quickly becoming the dominant machine learning algorithm until bootstrap aggregated decision trees were introduced in 1994. With the introduction of random forests and GBMs in 2001, followed by stochastic GBMs in 2002, the world suddenly had a wide variety of equally powerful machine learning methods for predictive tasks. Each of these introductions was followed by a flurry of interest, with new extensions to each model being proposed and new improvements bolted on. Whole fields of research rose up following the initial introduction of each algorithm. It wasn't until 2012 that neural networks, which we didn't have time for in this course, became extremely popular due to their success as image classifiers. It wasn't until 2014 that xgboost brought GBMs into the spotlight by making them consistently highly accurate; it wasn't until 2016 that lightgbm made them fast to train as well. --- Richard Hamming, in his book The Art of Doing Science and Engineering, offers a theory of how most fields develop over time. He suggests most fields grow in an S-curve fashion after being sparked by some initial innovation. Once that initial momentum slows, a new innovation is needed to kick growth off once again:  (This graph is pulled straight from his book, typos and all.) --- class: middle Here's my point. Machine learning is moving incredibly quickly, and it's hard to guess exactly where the field will be heading next. It seemed for ages that kernel-based methods like SVM would be consistently the best method for prediction, then it seemed for ages that decision trees were the way of the future. Fields grow exponentially, then plateau. Right now, a lot of attention is being spent on neural networks. And all that attention is producing good (or at least effective) results; our algorithmic culture is entirely powered by artificial neurons guessing what news story you'll click on or which video you'll enjoy. But I don't think that means we should believe that this time we got it right and that neural nets will always dominate the ML space. Maybe we'll go back to kernel methods, maybe decision trees, maybe something new altogether. I have no idea, but I think it's worth covering older options like SVMs just in case they take over once again. And hey, sometimes they work. --- class: middle I wanted to end with Hamming because of two quotes from his book I've had rattling around in my head while writing this course. The first one goes like this: <br /> > Education is what, when, and why to do things. Training is how to do it. <br /> And I've attempted to design this course to reach both ends. --- class: middle The second quote is: <br /> > Teachers should prepare the student for the student’s future, not for the teacher’s past. <br /> And, well, I hope I did. --- class: middle # References --- Titles are links: + [Hands-on Machine Learning Chapter 14](https://bradleyboehmke.github.io/HOML/svm.html) + [Richard W Hamming: The Art of Doing Science and Engineering](http://worrydream.com/refs/Hamming-TheArtOfDoingScienceAndEngineering.pdf)